- Considérations linguistiques
- Conventions de nommage des fichiers
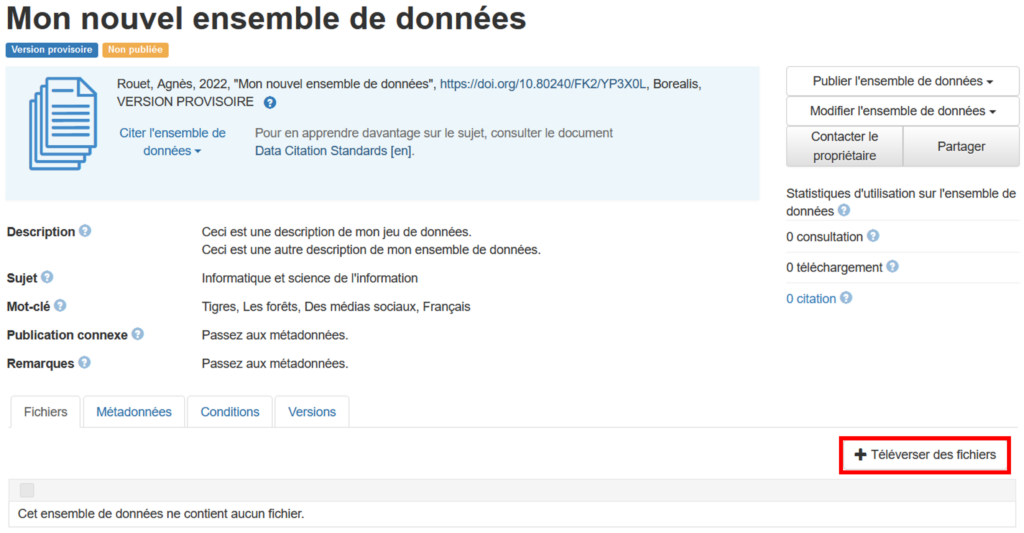
- Ajout de fichiers à un ensemble de données
- Formats de fichiers
- Réutilisation des données
- Limites de taille de fichier
- Limitations des fichiers uniques
- Limitations des fichiers compressés
- Limitations des fichiers tabulaires
- Téléchargements de fichiers par lots
- Fichier volumineux et principes FAIR
- Téléversement de fichiers vers un ensemble de données
- Glisser-déposer des fichiers
- Bouton Sélectionner les fichiers à ajouter
- Téléversement depuis Dropbox
- Remplacement de fichiers dans un ensemble de données publié
- Enregistrement des fichiers téléversés
- Intégration GitHub
- Saisie de métadonnées et restriction d’accès pour les fichiers
- Ajout de métadonnées lors du téléversement de fichiers
- Restriction d'accès à des fichiers
- Ingestion des fichiers tabulaires
- Limitations de l’ingestion de fichiers Excel
- Erreurs d’ingestion tabulaire
- Ignorer l'ingestion tabulaire
- Téléversement de fichiers ZIP
- Considérations relatives au fichier ZIP
- Outil de curation de données
- Hiérarchies de fichiers
Considérations linguistiques
Si vos noms de fichiers contiennent des caractères accentués, tels que é, ç ou ö, assurez-vous que le codage du fichier soit un codage UTF-8 qu’utilise le logiciel Dataverse. Si vous téléversez un fichier contenant des caractères accentués avec un codage différent, les accents seront supprimés. Vous pouvez utiliser la fonction Aide de votre application logicielle pour plus d’information sur la modification de l’encodage de votre fichier.
Conventions de nommage des fichiers
Les conventions de nommage des fichiers sont essentielles pour rendre vos données FAIR (faciles à trouver et faciles à comprendre). Ces conventions peuvent être déterminées lors de la phase de planification de la gestion des données de votre projet. Voici quelques conseils pour choisir une convention de nommage des fichiers pour votre projet.
Utilisez des noms de dossier courts et des noms de fichiers descriptifs :
Ceci est particulièrement important si vous n’indiquez pas le nom ou la structure du dossier de fichiers dans votre ensemble de données. Les gens n’auront pas de noms de dossier pour les aider à déchiffrer ce qui peut être contenu dans vos fichiers.
Évitez d’utiliser des symboles ou des signes de ponctuation :
N’utilisez pas les caractères qui apparaissent au-dessus des chiffres sur votre clavier ou d’autres types de ponctuation dans le nom de votre fichier (p. ex.,! @ # $ ^ & * ( ) + = ~ . ,? `).
N’utilisez pas d’espaces :
Utilisez un trait de soulignement (_), un trait d’union (-) ou des lettres majuscules pour séparer les mots ou les sections de votre nom de fichier, mais pas d’espace.
Par exemple, évitez « Nom du projet Titre de l’enquête Nom du répondant Sept 2020.doc » → utilisez plutôt « NomProjet_Enquete_NomduRepondant_Sep2020.doc » ou « Nom-Projet_Enquete_Nom-du-Répondant_Sep-2020.doc ».
Choisissez un format de date cohérent :
Classez les éléments des données par ordre chronologique : année, mois, jour (AAAA-MM-JJ ou AA-MM-JJ). Si vous devez également inclure l’heure, placez-la également dans l’ordre chronologique : heures, minutes, secondes (HHMMSS).
Par exemple, évitez « Nom-du-Répondant_2020_Mar_16-14 : 00.doc » ou « Nom-du-Repondant_03_16_2020-1400.doc » → utilisez plutôt « Nom-du-Repondant_2020-03-16-1400.doc ».
Utilisez une méthode cohérente de contrôle de version :
Alors que Borealis garde une trace des différentes versions d’un fichier téléversé dans un ensemble de données publié, ces versions ne sont pas reflétées dans le nom du fichier et ne reflètent pas votre version du fichier. Si vous avez plusieurs versions du même fichier, gardez une trace des versions en utilisant un format cohérent.
Un format suggéré est d’utiliser Vx-01 à Vx-99 pour les révisions mineures et V1-xx à V9-xx pour les révisions majeures. Vous pouvez également ajouter des mots tels que « Final » ou « Brouillon » pour mieux faire la distinction entre les versions principales.
Par exemple, utilisez « Nom-du-Projet_Article-de-Revue_V1-03.doc » ou « Nom-du-Projet_Article-de-Revue_V2-01.doc » ou « Nom-du-Projet_Article-de-Revue_V3_Final.doc ».
Documentez la convention de nommage des fichiers que vous avez utilisée :
Si vous incluez de la documentation avec votre ensemble de données dans le cadre de votre téléversement (p. ex., un fichier lisez-moi), incluez une description de la convention de nommage des fichiers que vous avez utilisée.
Ajout de fichiers à un ensemble de données
Vous pouvez ajouter un ou plusieurs fichiers lors de la création d’un nouvel ensemble de données, avant de cliquer sur le bouton Enregistrer l’ensemble de données. Vous pouvez également ajouter des fichiers à l’aide du bouton Téléverser des fichiers après que l’ensemble de données a été créé.
Formats de fichiers
Borealis prend en charge le téléversement de tout type de fichier, y compris (mais sans s’y limiter) des documents (PDF, DOCX, TXT, PPTX), des images (JPG, PNG, TIFF), des vidéos (MOV, MP4), des fichiers audios (MP3, WAV), des fichiers tabulaires (XLSX, SAV, DTA, R, CSV, TSV, TAB), des fichiers compressés (ZIP) et bien d’autres.
Réutilisation des données
Un aspect important de la réutilisation des données et des principes FAIR est la capacité d’une personne à pouvoir ouvrir, visualiser et manipuler le ou les fichiers à tout moment, maintenant et à l’avenir. Il y a différents éléments dont il faut tenir compte concernant les formats de fichiers : les conventions disciplinaires, à quel point il est facile (ou coûteux) d’obtenir le logiciel requis pour ouvrir un fichier et quelle est la probabilité que le format devienne obsolète.
Les fichiers qui ne peuvent être ouverts qu’avec des logiciels coûteux (p. ex., NVivo, SPSS, Stata, etc.) peuvent empêcher la visualisation ou l’utilisation de vos données. Les formats de fichiers qui peuvent devenir obsolètes (p. ex., WordPerfect, MS Works, etc.) peuvent signifier que votre fichier ne sera plus accessible à l’avenir.
Lors de la sélection des formats de fichiers que vous souhaitez utiliser dans votre ensemble de données, pensez à votre objectif ultime pour préserver et de donner accès à long terme à vos données de recherche. Si l’objectif est de rendre vos données de recherche disponibles à d’autres chercheurs pour analyse ou réutilisation, optez pour des formats de fichiers qui seront toujours utilisables (p. ex., des fichiers délimités par des virgules et des tabulations, des fichiers texte brut, des PDF, etc.).
Limites de taille de fichier
Borealis a des limites sur la taille des fichiers que vous pouvez téléverser.
Limitations des fichiers uniques
Lors du téléversement d’un seul fichier, ce fichier ne peut pas dépasser 5 Go.
Limitations des fichiers compressés
Lors du téléversement de plusieurs fichiers dans un fichier ZIP, le logiciel Dataverse décompresse le fichier et place les fichiers individuels dans votre ensemble de données. Les fichiers ZIP contenant plus de 1 000 fichiers ne seront pas décompressés en fichiers individuels.
Lors du téléversement de fichiers TAR ou de fichiers doublement compressés, la compression et l’organisation des fichiers seront maintenues.
Limitations des fichiers tabulaires
Lors du téléversement d’un fichier tabulaire (p. ex., XLSX, SAV, CSV, etc.), il est recommandé que le fichier ne dépasse pas 500 Mo. Lors du téléversement d’un fichier tabulaire, le logiciel Dataverse ingère et convertit ce fichier en un fichier pouvant être utilisé par n’importe quel logiciel tabulaire. Il ne peut effectuer cette conversion que pour les fichiers inférieurs à 500 Mo.
Lorsque le logiciel Dataverse ingère et convertit un fichier tabulaire, la sortie de ce processus (un fichier TAB) sera enregistrée en complément du fichier original et sera affichée dans votre ensemble de données. Le fichier d’origine peut être téléchargé si cette version est préférée.
Seule la première feuille d’un fichier de feuille de calcul sera ingéré et affiché dans le fichier TAB. Les feuilles supplémentaires ne seront pas incluses. La seule façon pour un utilisateur d’afficher toutes les feuilles de votre fichier de feuille de calcul est de télécharger la version du format de fichier d’origine.
Une solution de contournement potentielle pour les deux limitations ci-dessus consiste à créer des fichiers séparés pour chaque feuille de votre feuille de calcul. Si un fichier avec une seule feuille est encore trop volumineux pour être ingéré, vous pouvez créer une feuille de calcul distincte pour chaque période de vos données (p. ex., par semaine, par mois, par année, etc.).
Pour en savoir plus sur le processus d’ingestion de fichiers tabulaires, consultez le Guide de l’utilisateur avancé.
Téléchargements de fichiers par lots
Si vous avez beaucoup de fichiers décompressés à télécharger dans votre ensemble de données et que vous avez de l’expérience avec les outils à ligne de commande, vous pouvez envisager d’utiliser DVUploader pour téléverser des groupes de fichiers. Bien que les mêmes limitations de taille de fichier s’appliquent, cet outil vous fera économiser le temps et les efforts nécessaires pour ajouter des fichiers à partir du site web.
Pour en savoir plus sur DVUploader, consultez la documentation sur GitHub (en anglais).
Prenez note que Borealis ne supporte pas rsync + SSH upload.
Fichier volumineux et principes FAIR
Un aspect important de la réutilisation des données et des principes FAIR est la capacité d’une personne à obtenir vos fichiers. De nombreux pays, dont le Canada, ont des vitesses de connexion Internet très lentes à certains endroits et parfois les fournisseurs de services Internet peuvent limiter la quantité de données pouvant être téléchargée pendant certaines périodes. Ainsi, quelqu’un situé dans l’une de ces zones peut trouver difficile de télécharger un fichier volumineux à partir de votre ensemble de données. Gardez cela à l’esprit lorsque vous organisez vos ensembles de données. Essayez de garder les fichiers aussi petits que possible afin de permettre à tout utilisateur d’accéder à vos fichiers à l’avenir.
La taille d’un fichier peut également empêcher certains de traiter le fichier sur leur ordinateur, en fonction de la vitesse du processeur ou de la quantité de RAM. Le matériel informatique peut rapidement devenir obsolète et peut également empêcher un utilisateur de données de pouvoir faire quoi que ce soit avec un fichier de votre ensemble de données, même s’il a pu le télécharger.
Téléversement de fichiers vers un ensemble de données
Il existe trois façons d’ajouter des fichiers à un ensemble de données une fois sur l’écran de téléversement : en faisant glisser et en déposant les fichiers, en utilisant le bouton Sélectionner les fichiers à ajouter ou en téléchargeant vos fichiers depuis Dropbox.
Glisser-déposer des fichiers
- Utilisez l’explorateur de fichiers sur votre ordinateur et accédez aux fichiers que vous souhaitez téléverser.
- Cliquez sur un ou plusieurs des fichiers que vous souhaitez téléverser, puis faites glisser ces fichiers sur la fenêtre de votre navigateur web et dans la case qui dit Glisser-déposer les fichiers ici.
- Pour mettre en surbrillance plusieurs fichiers à la fois, cliquez sur le premier fichier, puis maintenez la touche Maj enfoncée tout en cliquant sur les autres fichiers.
Bouton Sélectionner les fichiers à ajouter
- Cliquez sur le bouton Sélectionner les fichiers à ajouter sur l’écran de téléversement de fichiers.
- Localisez les fichiers que vous souhaitez téléverser et cliquez sur le bouton Ouvrir ou Enregistrer.
- Pour mettre en surbrillance plusieurs fichiers, cliquez sur le premier fichier, puis maintenez la touche Maj enfoncée tout en cliquant sur les autres fichiers.
Téléversement depuis Dropbox
- Cliquez sur le bouton Téléverser à partir de Dropbox sur l’écran de téléversement de fichiers. Connectez-vous à votre compte DropBox, au besoin.
- Parcourez les fichiers de votre dossier Dropbox ; sélectionnez ceux que vous souhaitez télécharger, puis cliquez sur le bouton Choisir.
Remplacement de fichiers dans un ensemble de données publié
Une fois qu’un jeu de données est publié, la fonction Editer > Remplacer peut être utilisée pour mettre à jour ou réviser les fichiers existants dans le jeu de données. Le remplacement d’un fichier génère également une nouvelle version provisoire de l’ensemble de données, et cette fonction crée un lien entre la version précédente et la version actuelle de l’ensemble de données, afin de suivre l’historique du fichier dans les différentes versions de l’ensemble de données.

Les fichiers ayant la même somme de contrôle ou le même identifiant attribué de manière algorithmique peuvent être téléchargés dans un seul jeu de données. Si vous tentez de remplacer un fichier par un fichier dont la somme de contrôle MD5 est identique à celle d’un autre fichier de l’ensemble de données, un message d’avertissement s’affiche. En revanche, si vous tentez de remplacer un fichier par un autre dont la somme de contrôle est identique, un message d’erreur s’affiche et le fichier n’est pas remplacé.
Enregistrement des fichiers téléversés
- Une fois que vous avez commencé le téléversement de vos fichiers à l’aide de l’une des trois méthodes précédentes, vous devrez peut-être attendre quelques secondes à plus d’une heure. La vitesse de téléversement dépend d’une combinaison de la vitesse de votre connexion Internet et de la taille des fichiers que vous téléversez.
- Si le téléversement d’un fichier prend trop de temps ou si vous avez changé d’avis à propos du fichier, cliquez sur le bouton X à droite de la barre de progression pour arrêter le téléversement.
- Pour les fichiers de petite taille ou pour les connexions Internet rapides, vous ne verrez peut-être pas du tout la barre de progression et le bouton X.
- Passez en revue la liste des fichiers une fois qu’ils ont tous été téléversés.

- Accédez à la section Saisie de métadonnées pour les fichiers si vous souhaitez ajouter plus d’information sur chaque fichier avant de les enregistrer.
- Si vous avez inclus un fichier tabulaire dans votre téléversement, consultez la section d’ingestion de fichiers tabulaires pour plus d’information.
- Puis, cliquez sur le bouton Enregistrer les modifications pour terminer le téléversement.
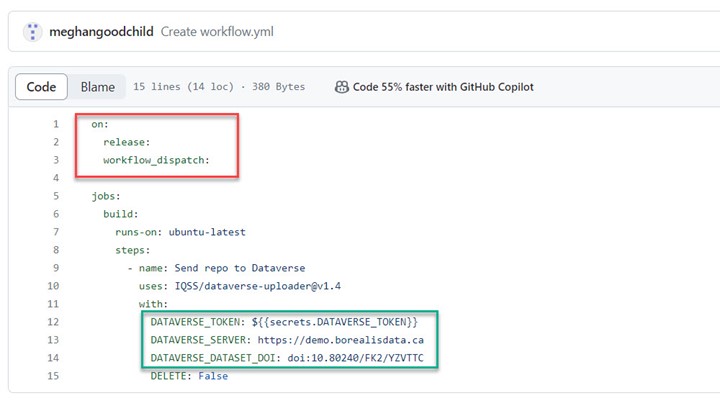
Intégration GitHub
Le contenu d’un dépôt GitHub peut être téléchargé dans un jeu de données Borealis existant, en utilisant une « action GitHub » appelée « Dataverse Uploader Action ». Cette intégration offre un moyen simplifié de sauvegarder votre dépôt Github dans un jeu de données Borealis. Cette action personnalisable peut vous permettre de :
- Télécharger l’intégralité du dépôt Github ou des sous-répertoires spécifiques.
- Synchroniser automatiquement lors d’événements déclencheurs (par exemple, push, release) ou manuellement à l’aide de l’événement d’envoi du flux de travail.
- Activer/désactiver la suppression du contenu des ensembles de données avant le téléchargement depuis GitHub.
- Activer/désactiver la publication automatique d’une nouvelle version du jeu de données.
Pour utiliser l’action GitHub :
- Au sein de votre dépôt GitHub, créez un fichier YML (c’est-à-dire workflow.yml) dans le répertoire appelé .github.workflows/.
- Saisissez vos configurations, telles que les événements déclencheurs, et indiquez si vous souhaitez télécharger l’ensemble du référentiel (par défaut) ou des sous-répertoires spécifiques.
- Ajoutez votre jeton API en tant que variable secrète
- Saisissez l’URL du serveur (par exemple, https://borealisdata.ca, https://demo.borealisdata.ca) et le DOI de l’ensemble de données (par exemple, doi:xx.xxxx/xxx/xxxxxx).
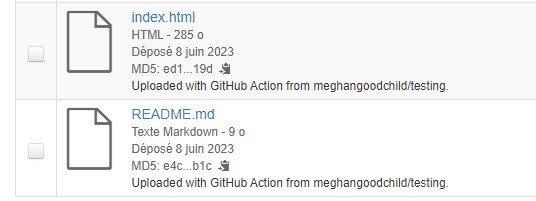
- Après que l’action GitHub ait téléchargé les fichiers vers Borealis, vous verrez les fichiers apparaître dans la liste des fichiers avec les métadonnées « Uploaded with GitHub Action from » avec le nom de votre dépôt en annexe.
Saisie de métadonnées et restriction d’accès pour les fichiers
Les métadonnées au niveau des fichiers, telles que les noms de fichiers, les chemins, les descriptions, l’information de provenance et les balises peuvent être ajoutées à chaque fichier pendant le processus de téléversement. Tous ces champs de métadonnées peuvent également être ajoutés ou modifiés après qu’un fichier a été téléversé dans un ensemble de données. Vous pouvez également restreindre et retirer les restrictions ici, tel que décrit à la section Restriction.
Ajout de métadonnées lors du téléversement de fichiers
Une fois qu’un fichier a été téléversé et que la barre de progression du téléversement a disparu, les renseignements de chaque fichier sont disponibles au bas de la page de téléversement. Les métadonnées au niveau du fichier peuvent être ajoutées à ce stade, avant de cliquer sur le bouton Enregistrer les modifications.
- Modifiez le nom du fichier dans le champ Nom de fichier, si vous souhaitez qu’il soit différent du nom de fichier que vous avez téléversé.

- Si vous souhaitez organiser vos fichiers dans une hiérarchie (qui est similaire à une structure de dossiers que vous trouverez sur votre ordinateur), il y a deux options
- Ajouter les métadonnées dans le chemin de chaque fichier afin d’indiquer la hiérarchie dans laquelle le fichier se retrouve (utilisez le format suivant): [Niveau_1]/[Niveau_2]/[Niveau_3]/… /[Niveau_x].
- Vous pouvez également télécharger un fichier ZIP contenant une structure ou une hiérarchie de fichiers, qui sera conservée dans votre ensemble de données.
- Saisissez des renseignements supplémentaires sur votre fichier dans le champ Description.
- Cliquez sur le bouton Modifier à droite pour modifier soit les libellés, soit la provenance associée au fichier.
- Passez à l’étape 5 si vous souhaitez modifier l’information de provenance.
- Passez à l’étape 6 si vous souhaitez modifier les libellés.
- Pour obtenir de l’information sur la provenance, suivez les instructions dans la page qui apparaît.
- Pour plus d’information sur la provenance des données, reportez-vous au Guide de l’utilisateur avancé.
- L’information sur la provenance doit être saisie pour chaque dossier.
- Si vous avez utilisé un outil de capture de provenance pour enregistrer l’historique de votre fichier, vous pouvez télécharger le fichier JSON dans la section Fichier de provenance.
- Si vous ne disposez pas du fichier de provenance JSON associé, vous pouvez saisir une description de l’historique de votre fichier dans le champ Description de la provenance.
- Cliquez sur le bouton Continuer lorsque vous avez terminé pour enregistrer l’information de provenance de ce fichier.
- Pour les libellés, vous pouvez soit sélectionner un ou plusieurs libellés existants, soit créer vos propres libellés personnalisés.
- Cochez la case à côté des noms de libellés existants (Documentation, Données ou Code) dans le menu déroulant Libellés de fichiers, si vous souhaitez en utiliser un ou plusieurs.
- Saisissez le nom d’une nouvelle balise dans le champ Libellés de fichier personnalisé et cliquez sur le bouton Appliquer pour ajouter ce libellé au fichier.
- Chaque libellé ajouté au fichier apparaîtra dans la section Libellés sélectionnés.
- Cliquez sur le bouton Enregistrer les modifications lorsque vous avez terminé d’ajouter des balises.
- Cliquez sur le bouton Enregistrer les modifications pour enregistrer tous les fichiers, ainsi que les métadonnées supplémentaires que vous avez saisies, dans votre ensemble de données.
Restriction d’accès à des fichiers
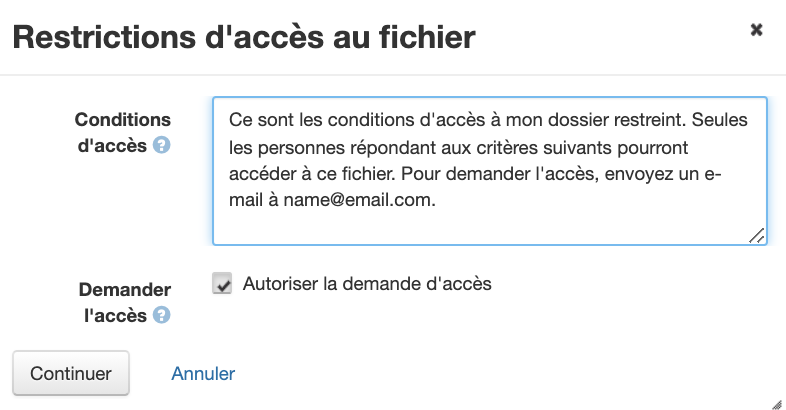
- Pour restreindre l’accès à un ou à plusieurs des fichiers que vous téléversez, commencez par cocher les cases associées aux fichiers à restreindre (à gauche), puis cliquez sur le bouton Modifier et sélectionnez Restreindre dans le menu déroulant.

- À la page Restrictions d’accès au fichier, entrez l’information sur les personnes autorisées à accéder à votre ou vos fichiers et comment elles peuvent obtenir l’accès dans le champ Conditions d’accès.
-
- Les ensembles de données auxquels l’accès aux fichiers est restreint doivent être assortis de conditions d’accès dans les métadonnées ou les demandes d’accès doivent être activées.
-
- Cochez la case à côté de Demander l’accès si vous souhaitez que les demandes d’accès passent par le logiciel Dataverse. Si vous ne cochez pas cette case, l’accès peut être demandé manuellement en contactant directement quelqu’un (selon les instructions du champ Conditions d’accès) ou par le bouton Contacter le propriétaire des données.
- Cliquez sur le bouton Continuer pour fermer la fenêtre.
- Cliquez sur Enregistrer les modifications.
Ingestion des fichiers tabulaires
Si vous téléversez des données tabulaires (p. ex., SPSS, STATA, RData, CSV et Excel), le logiciel Dataverse fera l’ingestion de vos fichiers tabulaires et les convertira en un fichier délimité par tabulation (TAB) qui peut être utilisé par tout logiciel tabulaire.Le processus d’ingestion tabulaire comporte de nombreux avantages, y compris la création d’une version non-propriétaire aux fins de préservation, une somme de contrôle UNF pour valider le contenu sémantique des dérivés, ainsi que des métadonnées DDi de niveau variable, qui peuvent être exportées en livre de code HTML au format DDI. L’ingestion tabulaire permet aussi de consulter les données avec l’Explorateur de données et permet la création de métadonnées de niveau variable avec l’Outil de curation des données.
Une fois que vous avez cliqué sur le bouton Enregistrer les modifications après avoir téléversé vos fichiers, vous pouvez voir une boîte verte Opération réussie ou une boîte jaune Ensemble de données verrouillé au haut de l’écran. Vous pouvez également voir une barre de progression bleue indiquant Chargement en cours… à côté du nom du fichier en cours de traitement.
Pendant le traitement de votre fichier tabulaire, vous ne pourrez pas apporter de modifications à votre ensemble de données. Plus votre fichier est volumineux, plus le temps de traitement sera long. Une fois le traitement terminé, une boîte verte apparaît au haut de l’écran indiquant que le fichier a été ingéré.
Une fois ingéré, votre fichier tabulaire apparaîtra désormais dans la liste des fichiers de votre ensemble de données, similaire à l’image ci-dessous. Le chemin d’accès du fichier, la description, les balises, la provenance et les restrictions de fichier sont les mêmes que lors du téléchargement, mais l’extension de fichier a été modifiée en TAB.

Limitations de l’ingestion de fichiers Excel
Le processus d’ingestion ne traitera que le premier onglet d’un tableur. Tous les autres onglets seront ignorés et ne seront pas inclus dans le fichier TAB créé. Si vous souhaitez que tous les onglets d’un fichier d’une feuille de calcul soient convertis au format TAB, vous devez télécharger chaque onglet dans son propre fichier.
Le fichier tabulaire préingéré que vous avez importé est enregistré dans le dépôt et peut être téléchargé. Cependant, la méthode de téléchargement peut ne pas être évidente pour les gens. Il peut être utile d’ajouter un commentaire dans le champ Description du fichier expliquant le format du fichier d’origine et indiquant qu’il est disponible pour téléchargement.
Erreurs d’ingestion tabulaire
Si vous recevez un message d’erreur lors de l’ingestion d’un fichier tabulaire, vous pouvez essayer de résoudre le problème de plusieurs façons. Cependant, vous pouvez également ignorer le message d’erreur. Bien que, le message d’erreur indique que le processus d’ingestion n’a pas fonctionné, votre fichier d’origine a quand même été téléversé.
Une icône d’avertissement s’affiche à côté de tout fichier pour lequel l’ingestion a échoué. Cependant, ce symbole est uniquement visible pour vous et les autres personnes qui peuvent modifier votre ensemble de données.

Remarque : Des parties des messages d’erreur peuvent s’afficher en anglais.
Erreurs d’ingestion courantes :
- L’ingestion de données tabulaires a échoué. Aucune ligne de données trouvée dans le fichier Excel (XLSX).
- Lorsque vous téléversez une feuille Google en tant que fichier Excel, elle utilise le format de feuille de calcul Office Open XML. Ce format n’est pas compris par le processus d’ingestion du logiciel Dataverse.
- Utilisez la fonction Enregistrer sous dans Excel pour réenregistrer le fichier en tant que fichier XLSX, puis téléversez à nouveau le fichier et il devrait suivre le processus d’ingestion sans erreur.
- Le fichier TAB produit à partir du fichier Excel enregistré peut ne pas avoir un nombre précis de lignes (ou d’observations) répertoriées dans Dataverse. Lorsque le fichier est enregistré, il peut inclure un certain nombre de lignes vides (ou d’observations).
- Échec de l’ingestion des données tabulaires. Incompatibilité de lecture, ligne x lors du deuxième passage : y valeurs délimitées attendues, z trouvé.
-
- Une raison possible pour cette erreur est un saut de ligne inclus dans l’une des cellules. Le message d’erreur indiquera sur quelle ligne ce saut de ligne se produit, afin qu’il puisse être corrigé.
- Supprimez le saut de ligne de la ligne indiquée, réenregistrez et téléversez à nouveau le fichier.
- Si plusieurs lignes ont un saut de ligne, l’ingestion continuera d’échouer jusqu’à ce qu’elles aient toutes été corrigées. Si vous avez un fichier volumineux, vous voudrez peut-être reformater le fichier à l’aide de formules au lieu d’effectuer des corrections manuellement.
-
- Échec de l’ingestion de données tabulaires. Ligne d’en-tête non valide. L’une des cellules est vide.
- Cette erreur se produit lorsqu’une cellule vide est incluse dans la ligne d’en-tête (ligne 1) entre deux cellules avec du texte. Dans un fichier CSV, cela signifie que la ligne d’en-tête a deux virgules consécutives : « texte 1,texte 2,texte 3,,texte 4,texte 5 »
- Entrez le texte dans la ou les cellules vides de la ligne d’en-tête, réenregistrez et téléversez à nouveau le fichier.
- Si une virgule a été incluse dans le texte d’un titre de cellule d’en-tête (p. ex., Ceci est une virgule, dans la cellule d’en-tête.), elle peut être laissée telle quelle tant que le texte est entouré de guillemets (p. ex., « Ceci est une virgule, dans la cellule d’en-tête. »).
- Aucune erreur, mais le fichier a une extension GSHEET ou NUMBERS.
- Le logiciel Dataverse n’ingère pas les fichiers Google Sheet (GSHEET) ou les fichiers Apple Numbers (NUMBERS).
- La version originale du fichier sera répertoriée dans votre ensemble de données.
- Enregistrez le fichier dans un format différent afin qu’il soit ingéré.
Si vous rencontrez d’autres problèmes d’ingestion ou si vous ne parvenez pas à résoudre les problèmes mentionnés ci-dessus, veuillez contacter votre établissement. Si vous ne souhaitez pas que vos fichiers ingérés par le processus d’ingestion tabulaire, communiquez avec l’équipe de Borealis.
Ignorer l’ingestion tabulaire
Les utilisateurs qui déposent des données à l’aide des API de Dataverse peuvent spécifier s’ils souhaitent ignorer le processus d’ingestion tabulaire pendant le processus de téléchargement.
- Pour ignorer le processus d’ingestion tabulaire, ajoutez le paramètre à l’appel API pour définir l’ingestion tabulaire sur false (la valeur par défaut est true).
- Pour plus de détails, voir la section « Ajout d’un fichier à un ensemble de données » dans le Guide d’utilisation avancé..
Il est également possible de demander à ce que les fichiers tabulaires ne soient pas ingérés, ce qui signifie que seul le type de fichier original est affiché et disponible pour le téléchargement. Contactez le soutien pour plus d’information.
Téléversement de fichiers ZIP
Les fichiers ZIP (compressés) peuvent être téléversés dans votre ensemble de données en utilisant la même méthode que tout autre format de fichier. Cependant, une fois le téléversement terminé, chaque fichier du fichier ZIP sera répertorié, au lieu d’un seul fichier ZIP. Le logiciel Dataverse décompresse la première couche de compression pendant le processus de téléversement.
Considérations relatives au fichier ZIP
Si vous souhaitez que votre fichier ZIP conserve son état compressé à l’intérieur de votre ensemble de données, vous devrez double compresser le fichier avant de le téléverser. (Cela signifie que vous devrez d’abord compresser les fichiers individuels dans un seul fichier ZIP, puis compresser à nouveau ce fichier ZIP. Essentiellement, le fichier a maintenant deux couches de compression.)
Le logiciel Dataverse décompresse toujours le fichier pendant son téléversement, mais il ne décompresse que le premier niveau de compression. Le deuxième niveau de compression est laissé tel quel et un fichier ZIP s’affiche dans votre liste de fichiers. Les gens peuvent ensuite télécharger le fichier ZIP et le décompresser sur leur propre ordinateur.
Il est possible de prévisualiser le fichier ZIP dans le navigateur et télécharger des fichiers individuels à l’aide de l’outil de prévisualisation ZIP.
Outil de curation de données
L’Outil de curation de données permet (pour les comptes avec droits d’administration, de curation ou de collaboration) de créer et modifier les métadonnées de niveau variable pour les fichiers tabulaires (p. ex., SPSS, R, XLSX, CSV). Les objectifs de cet outil sont d’améliorer le flux de travail de curation des données au sein du dépôt, d’améliorer la capacité de réutilisation des données et de soutenir l’application des normes et des meilleures pratiques à l’aide de la norme de métadonnées Data Documentation Initiative (DDI).
Pour utiliser l’outil de curation des données :
-
-
- Localisez le fichier tabulaire que vous souhaitez organiser.
- Il existe deux manières d’ouvrir l’Outil de curation de données pour un fichier.
- Option 1 : Dans la liste des fichiers de votre ensemble de données, cliquez sur l’icône Option de fichiers et sélectionnez Outil de curation de données.

- Option 2 : Sur la page du fichier, cliquez sur le bouton Modifier le fichier dans le coin supérieur droit, puis sélectionnez Outil de curation de données.
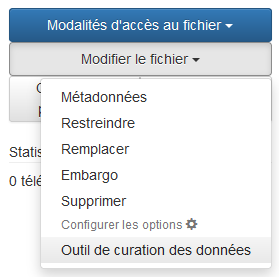
- Cliquez sur le bouton Continuer pour poursuivre.
- Un nouvel onglet s’ouvrira dans votre navigateur dans lequel le fichier tabulaire que vous avez sélectionné est maintenant affiché dans l’Outil de curation de données.

- Localisez le fichier tabulaire que vous souhaitez organiser.
-
Hiérarchies de fichiers
Les hiérarchies de fichiers peuvent être ajoutées à un ensemble de données : en ajoutant un chemin de fichier aux métadonnées du fichier ou en téléchargeant un fichier ZIP dans lequel les fichiers sont déjà organisés au sein d’une hiérarchie. La méthode du chemin de fichier, expliquée dans la section Saisie de métadonnées pour les fichiers, vous oblige à saisir manuellement le chemin de chaque fichier. La méthode ZIP effectue cette configuration automatiquement pour vous.
Lors du téléversement de fichiers ZIP dans un ensemble de données, il est automatiquement décompressé. Si le contenu du fichier ZIP comprend également des dossiers, cette structure est également conservée et ajoutée à l’ensemble de données.
À titre d’exemple, nous allons téléverser le fichier ZIP suivant (avec sa structure et ses fichiers) dans un ensemble de données.
Tester_le_fichier_ZIP_pour_le_téléchargement
- Analyse
- Feuilles_de_calcul
- XLSX_1
- Importer_des_fichiers
- CSV_1
- CSV_2
- Feuilles_de_calcul
- Documents
- Des_articles
- PDF_3
- PDF_4
- Rapports
- PDF_1
- PDF_2
- Des_articles
- Images
- Image_1
- Image_2
Sur la page Téléverser les fichiers de l’ensemble de données (affiché ci-dessous), une fois le fichier ZIP téléversé, vous verrez l’information incluse dans le champ Chemin d’accès au fichier pour chaque fichier. Ce texte décrit le chemin ou l’emplacement dans la hiérarchie où chaque fichier doit être localisé.

Une fois les modifications enregistrées sur la page Téléverser les fichiers de l’ensemble de données, les fichiers seront répertoriés dans l’ensemble de données. Lors de l’affichage de l’ensemble de données à l’aide de la vue Tableau, les fichiers seront répertoriés par ordre alphabétique. Les champs Chemin d’accès au fichier sont visibles pour chaque fichier, sous le nom du fichier.

Pour afficher les fichiers dans leur hiérarchie, cliquez sur le bouton Arborescence au-dessus du champ de recherche de l’ensemble de données.

L’Arborescence ou la vue hiérarchique de l’ensemble de données répertorie les fichiers dans leurs dossiers et dans l’ordre dans lequel ils ont été répertoriés dans le fichier ZIP. Alors que la vue Arborescence affiche les fichiers dans leur hiérarchie, contrairement à la vue Tableau, elle n’affiche aucune des métadonnées associées aux fichiers. Vous devrez cliquer sur chaque fichier pour afficher ses métadonnées associées.

Si votre ensemble de données complet est trop volumineux pour être téléchargé dans un seul fichier ZIP, téléchargez plusieurs fichiers ZIP avec la même structure de dossiers pour vous assurer que tous les fichiers se retrouvent dans la structure souhaitée.